


Transfer Learning with ULMFiT
Transfer Learning is one of the most important techniques used in the field of Deep Learning applications today. It is about the transfer of learned knowledge from a general to a specialized AI model. ULMFiT is a Natural Language Processing Method (NLP) developed in 2018 as part of the fast.ai framework under the direction of Jeremy Howard and implements a new exciting approach to transfer learning that we also present here.
We use Transfer Learning with ULMFiT especially for our information extraction solutions (see "Information Extraction with Deep Learning"). The main advantage is the small amount of data required to train the Deep Learning Model.
Transfer learning
Origin
Transfer Learning became known above all for its use in the field of image categorization. Today, various pre-trained versions of many popular deep learning models such as VGG-16, Inception V3 or ResNet-50 are available. For training purposes, more than 1.2 million images of the ImageNet platform were used to classify them into one of over 1,000 categories (classification). The pre-trained models can be used directly for new, own image classification applications. Only the last layers are replaced and trained by so-called classifiers.
Only later did Transfer Learning find its way into Natural Language Processing, where it is now indispensable. In both cases, Transfer Learning solves or mitigates the problem by reducing the number of data records.
Intuition behind pre-trained models
To distinguish and classify images, a model first learns how to build an image using simple elements such as edges and corners by applying filters. From these elements, more complex structures such as eyes, a nose or a mouth of a face are assembled. And so on. Each layer of a neural network "sees" the image at a certain level of abstraction and learns to distinguish patterns at that level. The identified patterns of all layers together finally form the basis for the prediction for which the model is trained. For example, which animal is to be seen on a picture? An image recognition application reuses all trained layers of the neural network except very last ones!
Natural language processing
The first Transfer Learning technique for NLP became known to a wider environment in 2013. Word2vec, GloVe and FastText are the most important representatives of this technology.
Word Embedding
In NLP applications, texts are typically considered word by word. Each word is assigned a unique number and texts are thus processed as streams of numbers. In word embedding, a word is represented not only by a single number, but by a vector with up to 500 numbers. These vectors are first learned independently of the actual AI task and then not only serve to distinguish the words, but also store additional information about the nature of the words. The teach-in takes place as part of a neural network using large text bodies such as the Wikipedia dataset of a language (the German version of Wikipedia currently contains approx. 2.2 million articles). In the skip-gram training method, just to pick one method out, the net is trained to predict which words occur in the immediate textual proximity to a particular other word. This allows the model to recognize not only similarly used words or synonyms, but also other similarities: Such as "apple" and "pear" (both types of fruit) or "mother" and "father" (both parents). But also relations between words are recognized: e.g. "father" to "son" behaves like "mother" to "daughter".
How does transfer learning work?
Pretty easy. The appropriate word embedding is used instead of a word as input for one's own neural network. If there is a lot of talk about apples in the training text, then the model can conclude that pears, bananas, mandarins or other fruit mean something similar and should therefore be treated similarly - without these words ever appearing in training texts.
Try it yourself
As part of a project to protect minors in online communities, we have generated a word embedding based on approximately 100 million chat messages originating from Austria (German language with Austrian dialect). At https://ai.calista.at you can try out which words are similar to the entered word. The result for "Wetter" (German for "weather") is:
Wetter --> wetta, regenwetter, sauwetter, herbstwetter, wettes, traumwetter, arschwetter, weter, regen, fr�hlingswetter
Depending on the frequency of the word in the chat, synonyms or misspellings are more likely to be displayed or, in case of more rare terms, words with a similar context, such as "ski":
Ski --> schi, snowboarden, snowboard, klettern, snowborden, schifahren, skifahren
Transfer learning with ULMFiT
Language model
ULMFiT not only uses word embedding, but uses the entire language model based on a recurrent neural network (AWD LSTM language model by Stephen Merity). The language model is trained exclusively on which word in a text is likely to come next. As a result, the model focuses more on typical phrases and phrases, and at the same time becomes familiar with relationships between the words.
Figure 1 shows the structure of the language model. The embedding layer (the lowest layer) corresponds to the word embedding. Unlike in the past, not only the embedding layer is reused, but also the entire RNN block (red border). RNN layers are elements of a neural network with an implicit feedback: Each word is first replaced in the embedding layer by the corresponding embedding vector and then - together with the RNN output of the preceding word - fed into the RNN layer as next input.
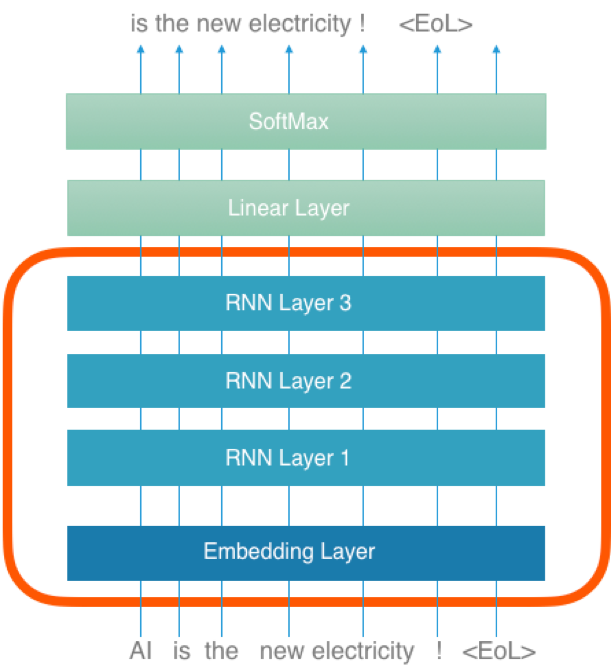 Figure 1: Structure of the voice model with ULMFiT
Figure 1: Structure of the voice model with ULMFiT
The text "AI is the new electricity!" serves in this example both as input and at the same time - but shifted by one word - as output. This is how the model learns to predict the next word.
Fine-tuning
It is obvious that a language model must be trained in the same language as the text for the later derived AI model. Ideally, however, the language domain (legal texts, literary texts, company sector-specific texts, etc.) should also match. Since this is rarely the case, ULMFiT provides a two-stage fine-tuning process. In the first step, the original language model is further trained with as many domain-specific texts as possible. Since again only the prediction of the "next" word is trained, no time-consuming labeling is necessary.
Knowledge transfer to your own model
The red block in figure 1 forms the basis for own AI models. The second fine-tuning step follows. The top two layers (above the red block) are only relevant for the language model itself and will not be reused. The knowledge transfer includes the configuration of the model as well as the trained weights of all transferred layers.
The ULMFiT creators also provide valuable advice for training the derived model. At first, only the new layers are trained. When the weights of these layers are filled with reasonably stable values, the entire neural network is trained further.
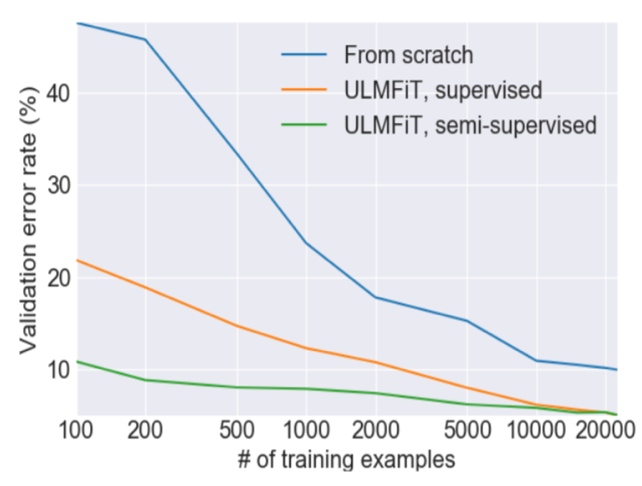 Figure 2: Error rate with/without ULMFiT
Figure 2: Error rate with/without ULMFiT
Figure 2 shows the advantage of ULMFiT as an example for a sentiment analysis model. The language model-based prediction model (green) achieves the same good error rate for only 100 documents, compared to the blue model (without transfer learning) which requires 10,000 documents.
Summary
Transfer Learning is a must. In AI Vision applications already for a long time, in NLP applications since 2013 at the latest since the advent of word embedding. ULMFiT combines the methods of AI Vision and word embedding and has developed one of the best methods for NLP transfer learning.
The use of pre-trained language models was the most important NLP trend of the year 2018. In addition to ULMFiT, the following approaches are also remarkable: ELMo, OpenAI Transformer and BERT.