Place a document in the business domain of Legal
Project Profile
Filing a document. With this project we show that it is possible to learn documents of different origin and type from a filing system in a secretary's office (default to filing) and to apply it to new documents. In this way, the secretary's office can be relieved of workload and the customer can be oriented to the filing requirements of the person requesting the documents.
At a glance - essential project data
| Duration | From 12/1/2018 to 12/1/2018 with about 2 months of full engagement | |
|---|---|---|
| Data and Tools | Market - Legal Sources • Exports from customer DB • 250 real documents • Generation of 10,000 synthetic documents | |
| Integration | Web API for metadata enrichment with model-generated data to be passed to the production system | |
| AI Methods | • NLP • Deep-Learning • Heuristics • ML-Statistics |
Engagement Use-Case
Filing of documents according to their individual filing date in the secretary's office.
Client motivation / Solution aims
- Replication of human filing characteristics of documents in a law firm
AI Approach
| AI key technology used in our solution | Multiple dates (approx. 20 dates) per legal document possible. Find the right date and put it on the "learned" push - trained unsupervised as a whole. | |
|---|---|---|
| Solution Approach | • NLP • Deep-Learning • Heuristics | |
| Project Approach | Simply agile | |
| Project Type | Proof-Of-Concept (POC) | |
| ML Integration and ML Operations | • Operation Integration API • VIsualizationAPI |
Insights and Details
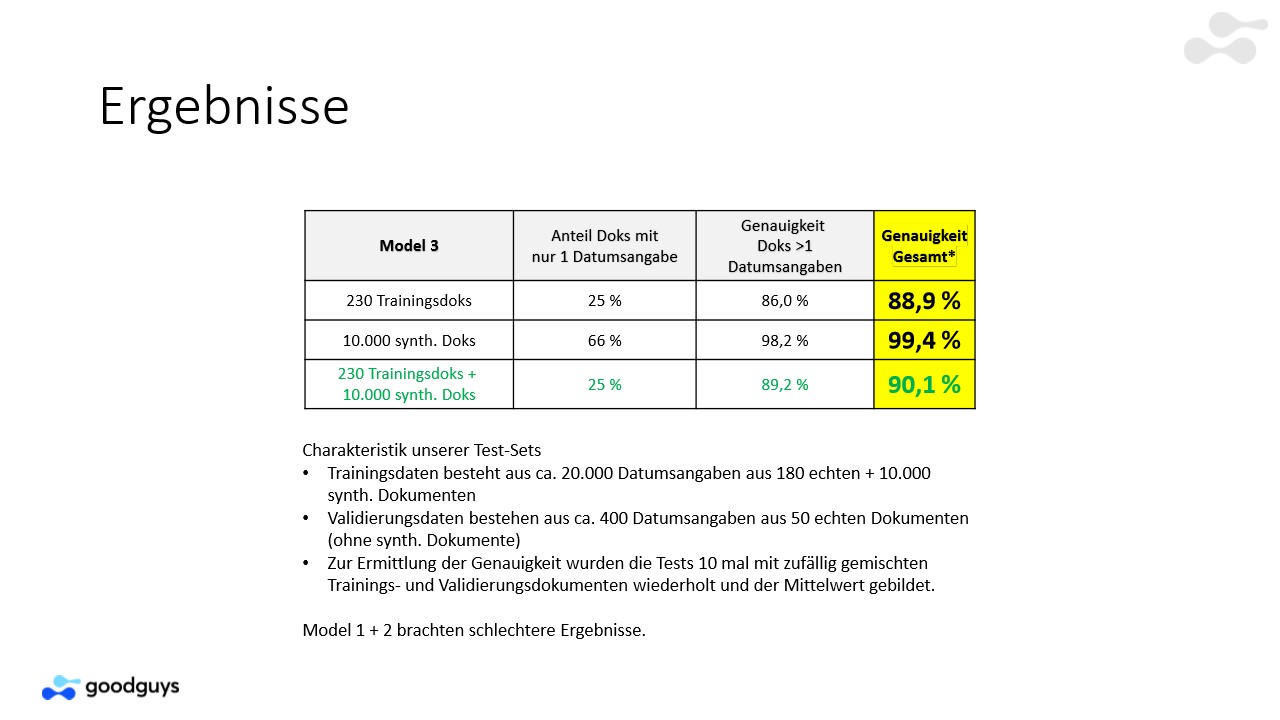
Multi-Model Approach Model 1 Results
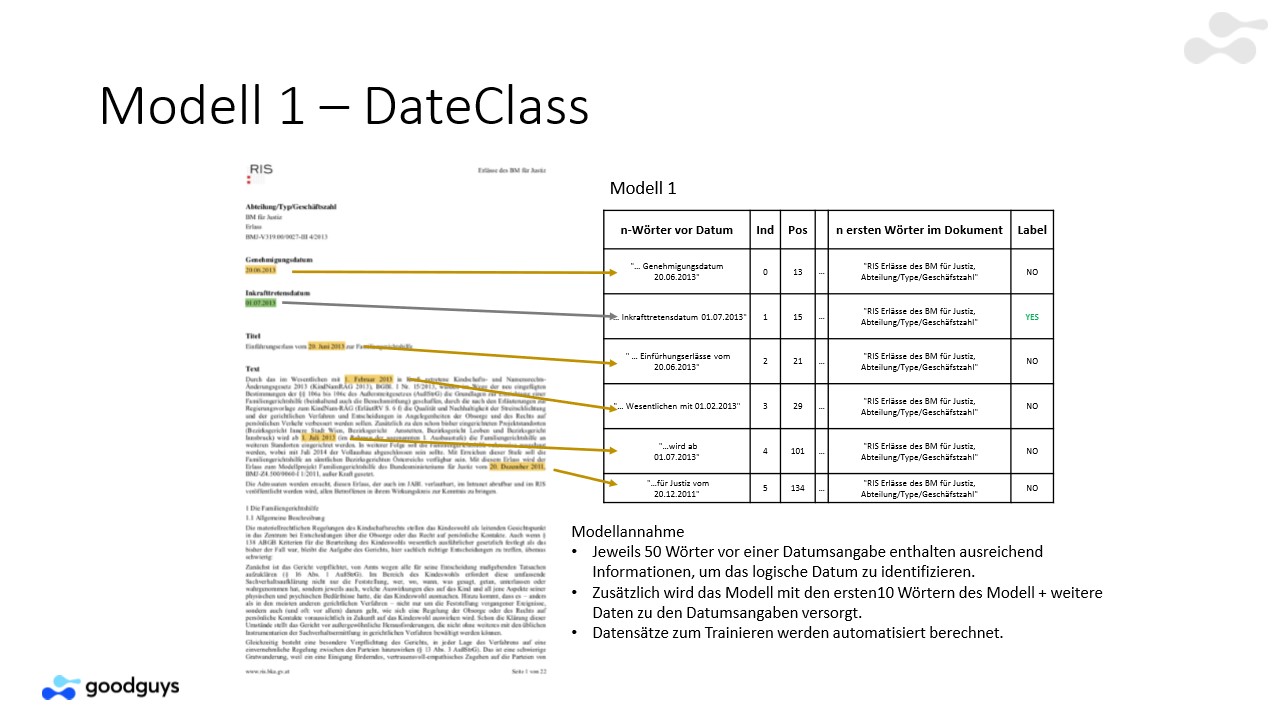
Multimodel Approach Model 2 Results

Multimodel Approach Model 3 Results including Topic Modeling to identify the topic Cluster of a Document. Learning with topcis and derived rules is easy!

Evaluation with a Deep-Learning Approach to identify the best result of a model. Working with all Models to get the best results.
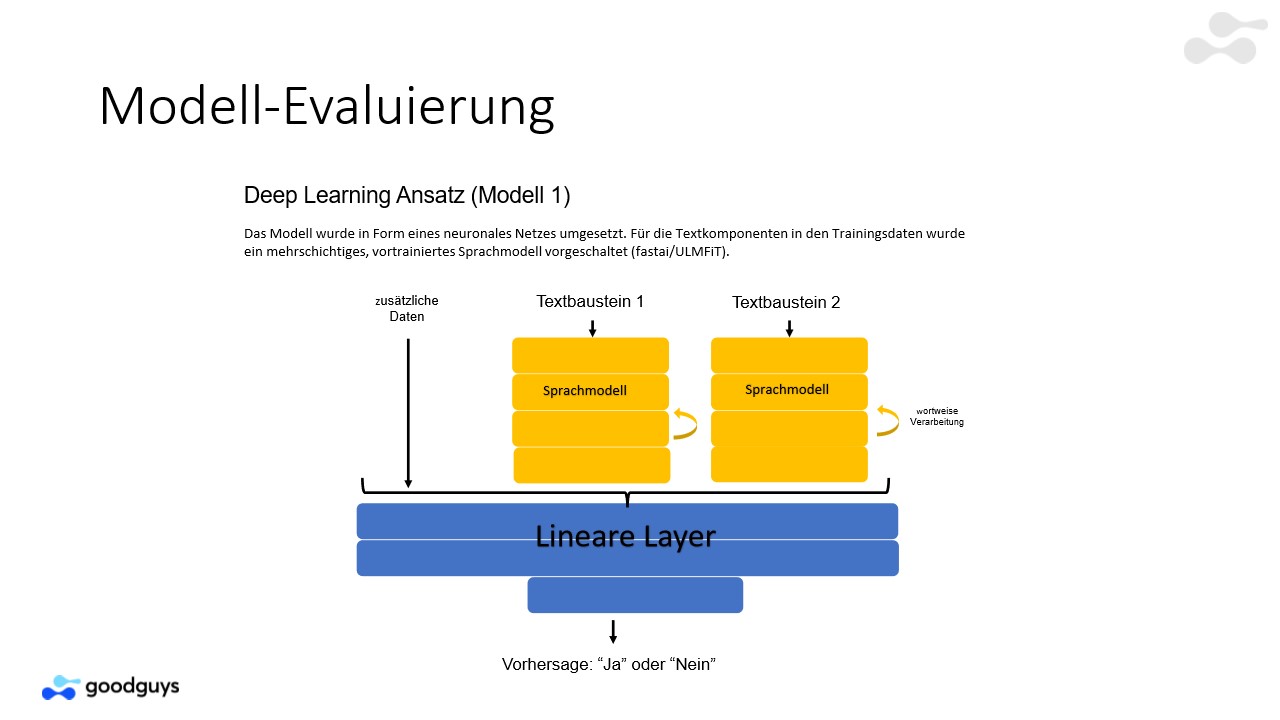
Showing the difference between model results and joint model results.