

"A Stony Road" - Deep Learning Based Approach for Information Extraction with only a few Training Documents
In this article we present an Artificial Intelligence application on information extraction under the paradigm of less training data. In the specific case, data (offers, documents, photos, emails) from the real estate industry were processed. However, the presented solution can also be trained and used for any other information from completely different industries with little effort.
The use-case "expos� reading"
A real estate company must continuously analyze and evaluate a large number of newly arrived expos�s with property offers. The differently structured expos�s are always searched for the same information: address of the plot, purchase price, achievable gross floor area, usable area, plot area, deal type and some others. At a effort of 10-20 minutes per expos�, many hundreds of hours of work are needed year after year just to work through the expos�s to pick out 5-10 objects at the end.
The AI development process
The most important stages of the development process were the labeling, the selection of the AI base method, the creation of the AI model up to the training and hyper-parameter tuning of the model.
Even labeling needs to be learned
Labeling determines what information should be found later with the help of the model. When labeling itself, the information you are looking for is virtually marked in the documents. These markers later serve as input for the training process. The effort for labeling is remarkable, because the quality of the later AI model depends directly on the care taken during this activity.
With each erroneous or forgotten label marking, the model learns something wrong that will later has a negatively impact the overall performance of the model. The upcoming blog entry "Labeling Tool for Information Extraction" will introduce our dedicated tool.
Our intelligence - choose the best AI base method
The number of training documents and the associated effort to label were an essential criterion in the selection of the AI method. In our case, 456 expos�s were available to train the model. Not all documents contained all the information sought. For example, price information, was found only in 373 expos�s, and details of the deal (asset / share) even in fewer than 150 documents.
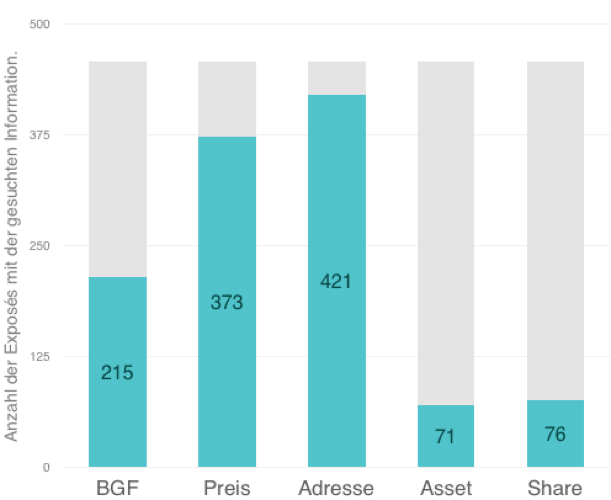 Figure 1: Number of expos�s with the searched information
Figure 1: Number of expos�s with the searched information
We have been looking for a method that achieves good results despite these unfavorable preconditions for deep learning applications. The Natural Language Processing (NLP) method, first developed in 2018, called ULMFiT (Universal Language Model Fine-tuning for Text Classification) uses the idea of "transfer learning" and fits very well into our schema. We have adapted this method, which is available in parts in the fast.ai framework, and developed a solution for information extraction from it.
Transfer learning with ULMFiT
Transfer Learning is about transferring already learned knowledge from one AI model to another. When a person tries to extract information from a text document, it is much easier for him, if he is familiar with the language used. AI models do not understand any language, but even the knowledge of how words are put together into phrases or sentences in one language is of great advantage for this purpose. So-called language models learn the structure of a language by trying to predict the next word in the context of a text. This prior knowledge leads to significantly better results in almost all text-related AI tasks. The advantage is particularly strong when only a few training data are available.
More detailed information can be found in our blog post "Transfer Learning with ULMFiT".
The model is crucial
The language model used is based on a recurrent neural network (RNN) consisting of an encoder and a decoder. The encoder, including all trained parameters, is transferred directly into the new model for information extraction. Whereas the decoder is replaced by new layers and is completely retrained.
Further information on the model used can be found in our upcoming blog post "Deep Learning Model for Information Extraction".
Training, hyper-parameter tuning and model optimization - survival of the fittest
Hyper parameters are the adjustment screws of AI models. The optimal configuration can be found by repeated training and subsequent analysis of the remaining errors or the accuracy achieved. In each cycle, about 80% of the documents are randomly selected for training and the remaining 20% are used to validate the results. If the achieved accuracy is not sufficient despite improved hyper parameters, you go back a step, make adjustments to the structure of the model and start again tuning the parameters.
Information extraction - a single pass
Each document goes through five steps in the process of obtaining information:
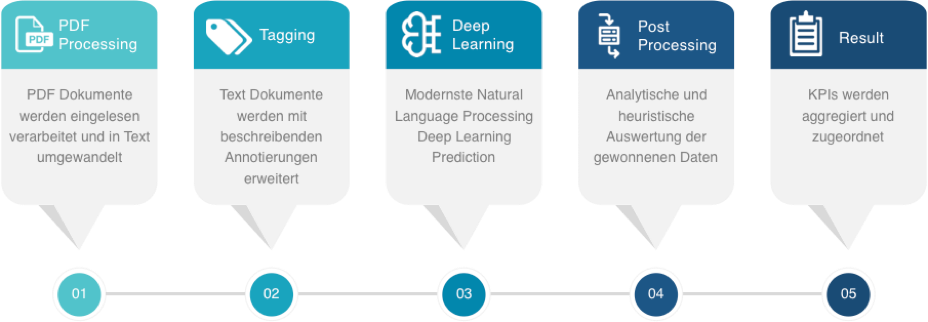 Figure 2: Sequence of the prediction process
Figure 2: Sequence of the prediction process
PDF processing
In the first step, the documents - in our case as PDF documents - are converted into pure text documents. Some of the documents contain images or consist partly of individually scanned pages. This task is performed by two competing OCR services (Google Vision and SolidFramework), which we have integrated.
Tagging
In the second preprocessing step, an automated marking (annotation) of information in the text takes place. The most important features in real estate expos�s are numbers, units of measurement and place or street names. This step uses purely heuristic methods, sometimes with the support of external data sources, and also counteracts the lack of training documents.
Deep learning
In this step, the document goes through our developed Deep Learning Model for Natural Language Processing. As a result, it provides a probability for each single word of the input document and for each individual piece of information searched for: the probability of whether or not it can be one of the searched-for information.
Post processing
The multitude of probabilities determined by the model are analyzed and evaluated. In addition, heuristic plausibility checks help to increase the quality of the results even further. Unsafe results are marked and can be fed in a further step of processing with possible manual post-control.
Result
In the last step, the extracted information is summarized and returned to the interface for further processing.
Project results at a�glance
Achieved accuracies
The following graph shows the accuracy of the model of selected information depending on the number of training documents. Clearly visible is already a relatively high accuracy with a small number of documents. The table itself was created using the cross-validation method. The model is often tested with a different selection of training and validation documents and the results are averaged.
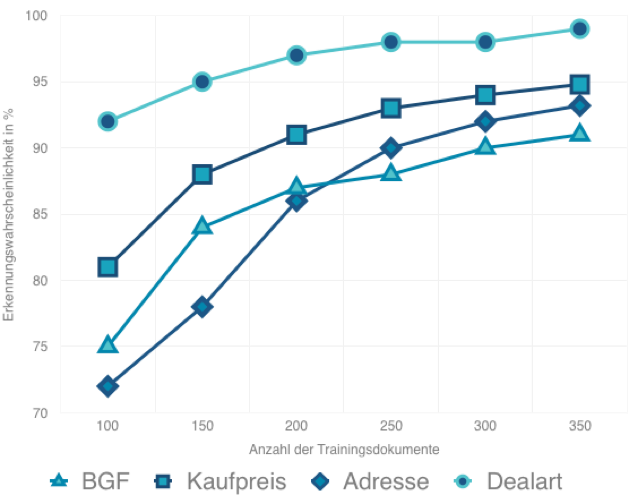 Figure 3: Achieved accuracies
Figure 3: Achieved accuracies
Challenges
During the implementation of this project, we faced a wide variety of challenges.
- Know-how building: In-depth knowledge of fast.ai is necessary to make adjustments to ULMFiT to the required extent.?
- Data: Real estate expos�s sometimes contain information about several objects. To distinguish which information can be assigned to which object, much more training data would be necessary. The advantages of Transfer Learning do not apply here.?
- Labeling: Labeling errors are detected, if at all, only when parsing the model's errors, and require time-consuming corrections, repetitive initiation of training cycles, and re-testing of tuned hyper parameters.?
- OCR: The search for a suitable OCR service was unexpectedly time-consuming. In order to be more tolerant of faulty text conversions, we recently used two OCR services in parallel.?
- Low number of training documents: Three strategies have ultimately led to a successful implementation. The integration of a language model (Transfer Learning), the tagging of the input documents and subsequent heuristic plausibility checks.?
Arrived? Not a long time, but a short interim rest is allowed.
That's just the beginning. We know how the journey can look like to implement AI solutions with just enough basic material.
We have achieved this:
- Label interface: Flexible and extensible label platform for individual labeling
- Tagging process: Automated labeling of basic information (addresses, names, numbers) is available and can be extended at will.
- Hyper parameter Optimization: Pragmatic optimization process for exploiting the potentials of the training data, if only less available.
- Result evaluation: Interface for training and optimization processes.
Stay tuned and know what to do next! This will make your learning curve steeper even in unknown areas! NLP will be the new prodigy of the industries for AI-based custom processing of huge mountains of documents.
Solution partner AI Consulting - goodguys.cc
Our Artificial Intelligence and Machine Learning approaches are fast, flexible and understandable. It must be fun to use knowledge and technology to make the topic usable. Exactly this worked out successfully together with Mr. Dr. F�richt from Goodguys The AI Network: https://goodguys.cc
About Calista
For more than four years we have been dedicated to the development of AI know-how. We rely on classical machine learning as well as deep learning methods. In addition to the focus NLP, we also deal with the DL subject areas Visual Imaging and Structured Data. We Go The AI Way. https://calista.at