


Transfer Learning mit ULMFiT
Transfer Learning ist heute eine der wichtigsten eingesetzten Techniken in Deep Learning Anwendungen. Es geht dabei um die Ðbertragung gelernten Wissens von einem allgemeinen zu einem spezialisierten AI Modell. ULMFiT ist eine Natural Language Processing Methode (NLP), die im Jahr 2018 als Teil des fast.ai Frameworks unter der Leitung von Jeremy Howard entwickelt wurde und einen neuen spannenden Ansatz f¸r Transfer Learning umsetzt, den wir hier ebenso vorstellen.
Wir selbst setzen Transfer Learning mit ULMFiT vor allem f¸r unsere Informationsextraktionslˆsungen (siehe "Information Extraktion mit Deep Learning" ein. Der wesentliche Vorteil ist die geringe Datenmenge, die zum Trainieren des Deep Learning Models notwendig ist.
Transfer Learning
Ursprung
Transfer Learning wurde vor allem durch seinen Einsatz im Bereich der Bildkategorisierung bekannt. Von vielen popul‰ren Deep Learning Modellen wie VGG-16, Inception V3 oder ResNet-50 stehen heute verschiedene vortrainierte Versionen bereit. Zum Trainieren wurden dazu meist die ¸ber 1.2 Millionen Bilder der ImageNet Plattform verwendet, die ¸ber 1.000 Kategorien zugeordnet wurden (Klassifizierung). Die vortrainierten Modelle kˆnnen direkt f¸r neue, eigene Bild-Klassifizierungsanwendungen ¸bernommen werden. Nur die letzten Schichten werden durch sogenannte Klassifier ersetzt und antrainiert.
Erst sp‰ter hielt Transfer Learning Einzug in das Natural Language Processing, wo es heute nicht mehr wegzudenken ist. In beiden F‰llen lˆst bzw. mildert Transfer Learning das Problem zu weniger Datens‰tze.
Intuition hinter vortrainierter Modelle
Um Bilder zu unterscheiden bzw. zu klassifizieren lernt ein Modell zun‰chst durch die Anwendung von Filtern wie ein Bild mit einfachen Elementen wie Kanten und Ecken aufgebaut werden kann. Aus diesen Elementen werden dann wiederum komplexere Strukturen wie z.B. Augen, Nase oder Mund eines Gesichtes zusammengesetzt. Und so weiter. Jede Schicht eines neuronalen Netzes "sieht" das Bild in einem bestimmten Abstraktionslevel und lernt Muster auf dieser Ebene zu unterscheiden. Die identifizierten Muster aller Schichten zusammen bilden am Ende die Grundlage f¸r die Vorhersage, f¸r die das Modell trainiert wird. Z.B. welches Tier auf einem Bild zu sehen ist. Bei der Bilderkennung kˆnnen alle trainierten Schichten des neuronalen Netzes bis auf die allerletzten wiederverwendet werden!
Natural Language Processing
Die erste Transfer Learning Technik f¸r NLP wurde 2013 einem breiteren Umfeld bekannt. Word2vec, GloVe und FastText sind heute die wichtigsten Vertreter dieser Technik.
Word-Embedding
In NLP Anwendungen werden Texte typischerweise wortweise betrachtet. Jedem Wort wird dabei eine eindeutige Zahl zugeordnet und Texte somit als Zahlenstrˆme verarbeitet. Beim sogenannten Word-Embedding wird ein Wort nicht nur durch eine einzelne Zahl, sondern durch einen Vektor mit bis zu 500 Zahlen repr‰sentiert. Diese Vektoren werden zuerst unabh‰ngig von der eigentlichen AI Aufgabe eingelernt und dienen dann nicht nur zur Unterscheidung der Wˆrter, sondern speichern zus‰tzlich Informationen ¸ber die Natur der Wˆrter. Das Einlernen erfolgt als Teil eines neuronalen Netzes mittels groþer Textkˆrper wie z. Bsp. des Wikipediadatensatzes einer Sprache (die deutsche Version von Wikipedia umfasst derzeit ca. 2.2 Mio Artikeln). Bei der Skip-Gram Trainingsmethode, nur um eine Methode herauszugreifen, wird das Netz trainiert vorherzusagen, welche Wˆrter in der unmittelbaren textuellen N‰he zu einem bestimmten anderen Wort vorkommen. Dadurch erkennt das Modell nicht nur ‰hnlich verwendete Wˆrter oder Synonyme, sondern auch andere Gemeinsamkeiten: Wie z. Bsp. "Apfel" und "Birne" (beides Obstsorten) oder ?Mutter? und ?Vater? (Elternteile). Aber auch Relationen zwischen Wˆrtern werden erkannt: Z.B. das sich "Vater" zu "Sohn" wie "Mutter" zu "Tochter" verh‰lt.
Wie funktioniert der Transfer des Gelernten?
Relativ einfach. Als Input f¸r das eigene neuronale Netz wird anstelle eines Wortes das entsprechende Word-Embedding eingesetzt. Ist im eigenen Text zum Trainieren nun ˆfters von ƒpfeln die Rede, dann kann das Modell schlussfolgern, dass mit Birnen, Bananen, Mandarinen oder sonstigem Obst etwas ƒhnliches gemeint ist und somit ‰hnlich zu behandeln sind ? ohne das diese Wˆrter jemals in Trainingstexten vorgekommen sind.
Selbst ausprobieren
Im Rahmen eines Projektes zum Jugendschutz f¸r Online Communities haben wir ein solches ein Word-Embedding auf Basis von ca. 100 Mio aus ÷sterreich stammenden Chatnachrichten generiert. Unter https://ai.calista.at kann ausprobiert werden, welche Wˆrter ‰hnlich zum eingegebenen Wort ist. Das Ergebnis zu "Wetter" lautet dabei:
Wetter --> wetta, regenwetter, sauwetter, herbstwetter, wettes, traumwetter, arschwetter, weter, regen, fr¸hlingswetter
Abh‰ngig von der H‰ufigkeit des Wortes im Chat werden eher Synonyme bzw. Falschschreibweisen angezeigt oder bei selteneren Begriffen Wˆrter mit ‰hnlichem Kontext, wie z.B. beim Wort "Ski":
Ski --> schi, snowboarden, snowboard, klettern, snowborden, schifahren, skifahren
Transfer Learning mit ULMFiT
Sprachmodell
ULMFiT verwendet nicht nur Word-Embeddings, sondern nutzt das gesamte Sprachmodell basierend auf einem Rekurrenten Neuronalen Netzwerk (AWD LSTM language model von Stephen Merity). Das Sprachmodell wird dabei ausschlieþlich darauf trainiert, welches Wort in einem Text wahrscheinlich als n‰chstes kommt. Dadurch konzentriert sich das Modell st‰rker auf typische Wortfolgen und Phrasen und lernt zugleich Zusammenh‰nge zwischen den Wˆrtern kennen.
Darstellung 1 zeigt den Aufbau des Sprachmodells. Der Embedding Layer (die unterste Schicht) entspricht dem Word-Embedding. Im Gegensatz zu fr¸her wird nicht nur der Embedding Layer wiederverwendet, sondern zus‰tzlich der gesamte RNN Block (rote Umrandung). RNN Layer sind Elemente eines neuronalen Netzwerkes mit einer impliziten R¸ckkoppelung: Jedes Wort wird zuerst im Embedding Layer durch den dazugehˆrigen Embedding-Vektor ersetzt und danach ? gemeinsam mit dem r¸ckgekoppelten RNN-Output des vorangegangenen Wortes ? als Input in den RNN Layer gef¸hrt.
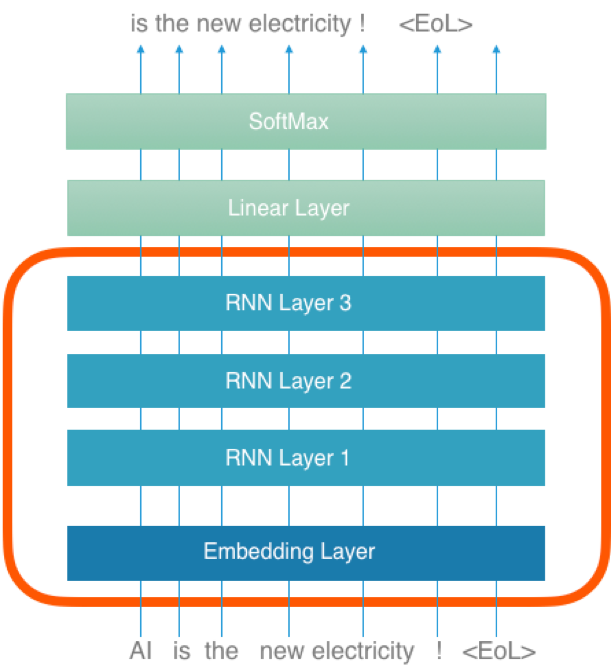 ?
Darstellung 1: Aufbau des Sprachmodels bei ULMFiT
?
Darstellung 1: Aufbau des Sprachmodels bei ULMFiT
Der Text "AI is the new electricity !" dient in diesem Beispiel sowohl als Input und zugleich ? aber um ein Wort versetzt ? als Output. Das Model lernt dadurch das jeweils n‰chste Wort vorherzusagen.
Finetuning
Es ist offensichtlich, dass ein Sprachmodell in derselben Sprache trainiert werden muss, in der auch die Texte f¸r das sp‰tere davon abgeleiteten AI Modell vorliegen. Optimalerweise sollte aber auch die Sprachdom‰ne (juristische Texte, literarische Texte, unternehmensbranchenspezifische Texte, etc.) ¸bereinstimmen. Da dies nur selten der Fall ist, sieht ULMFiT einen zweistufigen Finetuning Prozess vor. Im ersten Schritt wird das urspr¸ngliche Sprachmodell mit mˆglichst vielen dom‰nenspezifischen Texten weitertrainiert. Da wiederum nur das Vorhersagen des ?n‰chsten? Wortes trainiert wird, ist dazu kein aufw‰ndiges Labeln notwendig.
Wissenstransfer zum eigenen Modell
Der rote Block in Darstellung 1 bildet die Basis f¸r eigene AI Modelle. Der zweite Finetuning-Schritt folgt. Die obersten beiden Schichten (oberhalb des roten Blockes) dienen nur zum Trainieren des Sprachmodells selbst und werden nicht weiterverwendet. Der Transfer beinhaltet sowohl die Konfiguration des Modells als auch die trainierten Gewichte aller ¸bernommenen Schichten.
F¸r das Trainieren des abgeleiteten Modells halten die ULMFiT Schˆpfer ebenso wertvolle Ratschl‰ge bereit. Im ersten Trainingsschritt werden nur die neuen Schichten trainiert. Erst wenn die Gewichte dieser Schichten mit halbwegs stabilen Werten bef¸llt sind, wird mit dem gesamten neuronalen Netz weitertrainiert.
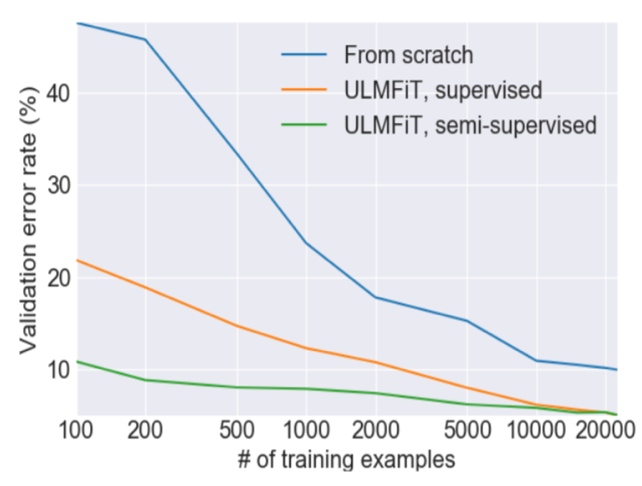 Darstellung 2: Fehlerrate mit/ohne ULMFiT
Darstellung 2: Fehlerrate mit/ohne ULMFiT
Darstellung 2 zeigt den Vorteil von ULMFiT exemplarisch f¸r ein Sentiment Analyse Modell. Das Sprachmodell-basierte Vorhersagemodell (gr¸n) erzielt bei nur 100 Dokumente dieselbe gute Fehlerrate wof¸r im Vergleich dazu das blaue Modell (ohne Transfer Learning) 10.000 Dokumente benˆtigt.
Zusammenfassung
Transfer Learning ist ein Muss. In AI Vision Anwendungen schon l‰ngst, in NLP Anwendungen sp‰testens seit 2013 seit dem Aufkommen der Word-Embedding. ULMFiT vereint die Methoden aus AI Vision und der Word Embeddings und hat daraus eines aktuell besten Methoden f¸r NLP Transfer Learning entwickelt.
Der Einsatz vortrainierter Sprachmodelle war der wichtigste NLP Trend des Jahres 2018. Neben ULMFiT sind auch folgende Lˆsungsans‰tze bemerkenswert: ÝELMo, OpenAI Transformer und BERT.