

"Ein steiniger Weg" - Deep Learning basierte Extraktion von Informationen mit nur wenigen Trainingsdokumenten
In diesem Beitrag stellen wir eine Künstliche Intelligenz Anwendung zum Thema Informationsextraktion unter dem Paradigma von geringen Trainingsdaten vor. Im konkreten Fall wurden Daten (Angebote, Dokumente, Fotos, eMails) aus der Immobilienbranche verarbeitet. Die vorgestellte Lösung lässt sich aber ebenso für beliebig andere Informationen aus völlig anderen Branchen mit geringem Aufwand anlernen und einsetzen.
Ausgangslage
Ein Immobilienkonzern muss laufend eine große Anzahl neu eintreffender Exposčs mit Grundstücksangeboten analysieren und bewerten. Die unterschiedlich strukturierten Exposés werden dabei immer auf dieselben Informationen durchsucht: Adresse des Grundstückes, Kaufpreis, erzielbare Bruttogrundfläche, Nutzfläche, Grundfläche des Grundstückes, Dealart und einige andere. Bei einem Aufwand von 10-20 min pro Exposé werden Jahr für Jahr viele hunderte Arbeitsstunden nur für das Durcharbeiten der Exposés benötigt, um sich am Ende für 5-10 Objekte zu entscheiden.
Der AI Entwicklungsprozess
Die wichtigsten Stufen des Entwicklungsprozesses waren das Labeln, die Auswahl der KI Basis-Methode, die Erstellung des KI-Modells bis hin zum Trainieren und Hyperparameter-Tunen des Modells.
Auch Labeln will gelernt sein
Durch das Labeln wird festgelegt welche Informationen später mit Hilfe des Modells gefunden werden sollen. Beim Labeln selbst werden quasi die gesuchten Informationen in den Dokumenten markiert. Diese Markierungen dienen später als Input für den Trainingsprozess. Der Aufwand für das Labeln ist bemerkenswert, denn die Qualität des späteren KI-Modells hängt direkt von der Sorgsamkeit während dieser Tätigkeit ab.
Mit jeder fehlerhaften oder vergessenen Label-Markierung lernt das Modell etwas Falsches, dass sich später negativ auf die Gesamtperformance des Modells auswirkt. In dem in Kürze verfügbaren Blogeintrag "Labelling Tool für Informationsextraktion" stellen wir unser dafür eingesetztes Werkzeug vor.
Unsere Intelligenz - wähle die Beste KI-Basis-Methode
Die Anzahl der Trainingsdokumente und der damit verbundene Aufwand zum Labeln waren ein wesentliches Kriterium bei der Auswahl der KI Methode. In unserem Fall standen 456 Exposés zum Trainieren des Modells zur Verfügung. Nicht in allen Dokumenten fanden sich alle gesuchten Informationen. Angaben zum Preis fanden sich zum Beispiel nur in 373 Exposés, Angaben zur Dealart (Asset/Share) sogar nur in weniger als 150 Dokumenten.
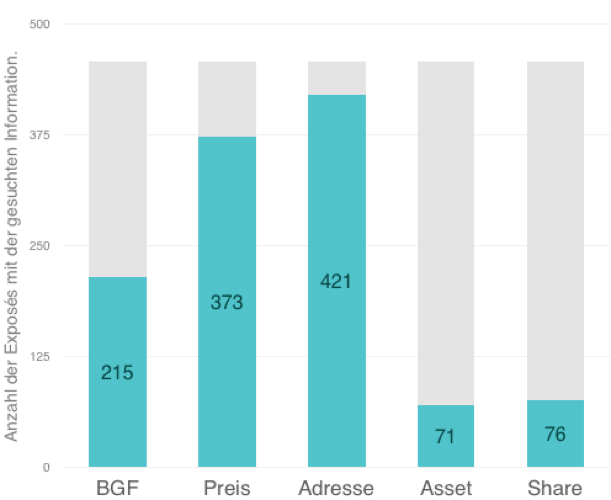 Darstellung 1: Anzahl der Exposés mit den gesuchten Informationen
Darstellung 1: Anzahl der Exposés mit den gesuchten Informationen
Wir haben nach einer Methode gesucht, die trotz dieser für Deep Learning Anwendungen ungünstigen Vorbedingungen gute Ergebnisse erzielt. Die erst 2018 entwickelte Methode zur Verarbeitung der natürlichen Sprache (Natural Language Processing, NLP) namens ULMFiT (Universal Language Model Fine-tuning for Text Classification) bedient sich der Idee des ?Transfer Learnings? und passte sehr gut in unser Schema. Wir haben diese Methode, die in Teilen im fast.ai Frameworks zur Verfügung steht, adaptiert und daraus eine Lösung zur Informationsextraktion weiterentwickelt.
Transfer Learning mit ULMFiT
Beim Transfer Learning geht es um die Übertragung eines bereits erlernten Wissens von einem KI Modell auf ein anderes. Versucht ein Mensch Informationen aus einem Textdokument zu extrahieren, fällt es ihm wesentlich leichter, wenn er die Sprache, in der das Dokument verfasst wurde, gut versteht. KI-Modelle verstehen zwar keine Sprache, aber bereits das Wissen wie in einer Sprache Wörter zu Phrasen bzw. zu Sätzen zusammengesetzt werden, ist für diesen Zweck von großem Vorteil. Sogenannte Sprachmodelle erlernen die Struktur einer Sprache, indem sie versuchen im Kontext eines Textes das jeweilige nächste Wort vorherzusagen. Dieses Vorwissen führt bei fast allen Text-bezogenen KI-Aufgaben zu wesentlich besseren Ergebnissen. Der Vorteil kommt besonders dann stark zum Tragen, wenn nur wenige Trainingsdaten bereitstehen.
Ausführlichere Informationen dazu finden Sie in unserem Blogbeitrag "Transfer Learning mit ULMFiT".
Das Modell ist entscheidend Das eingesetzte Sprachmodell basiert auf einem rekurrenten neuronalen Netzwerk (RNN) bestehend aus einem Encoder und einem Decoder. Der Encoder wird inklusive aller eintrainierten Parameter direkt in das neue Modell für die Informationsextraktion übernommen. Anstelle des Decoders wurden neue Layer modelliert und trainiert.
Weiterführende Informationen zum verwendeten Modell finden Sie in Kürze in unserem Blog "Deep Learning Modell für Informationsextraktion".
Trainieren, Hyperparameter Tuning und Modelloptimierung - "Survival of the fittest"
Hyperparameter sind die Einstellschrauben von KI-Modellen. Die optimale Konfiguration findet man durch wiederholtes Trainieren und anschließendem Analysieren der verbliebenen Fehler bzw. der erzielten Genauigkeit. In jedem Zyklus werden dazu etwa zufällige 80% der Dokumente zum Trainieren ausgewählt und die restlichen 20% zum Validieren der Ergebnisse verwendet. Ist die erzielte Genauigkeit trotz verbesserter Hyperparameter nicht ausreichend, geht man einen Schritt zurück, nimmt Anpassungen an der Struktur des Modells vor und beginnt erneut mit dem Tunen der Hyperparameter.
Die Informationsextraktion - ein Durchlauf
Jedes Dokument durchläuft im Zuge der Informationsgewinnung fünf Verarbeitungsschritte:
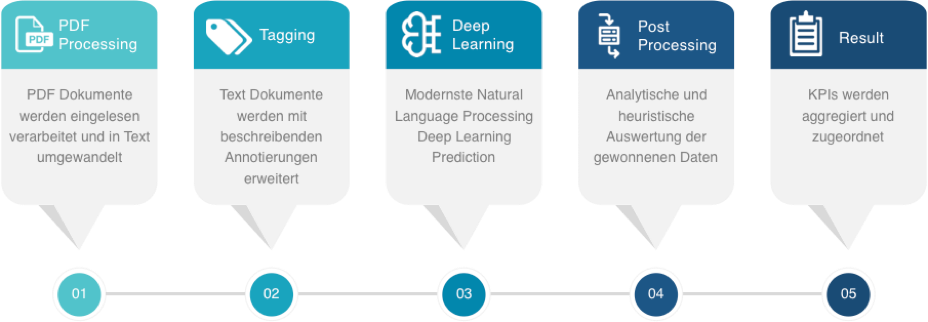 Darstellung 2: Ablauf des Vorhersageprozesse
Darstellung 2: Ablauf des Vorhersageprozesse
PDF Processing
Im ersten Schritt werden die - in unserem Fall als PDF - vorliegenden Dokumente in reine Textdokumente umgewandelt. Die Dokumente enthalten zum Teil Bilder bzw. bestehen teilweise gänzlich aus einzeln eingescannten Seiten. Diese Aufgabe wird von zwei zueinander konkurrenzierenden OCR Diensten übernommen (Google Vision und SolidFramework), welche wir integriert haben.
Tagging
Im zweiten Vorverarbeitungsschritt erfolgt ein automatisiertes Kennzeichnen (Annotieren) von Informationen im Text. Die wichtigsten Merkmale in Immobilienexposés sind Zahlenangaben, Maßeinheiten und Orts- bzw. Straßennamen. Dieser Schritt erfolgt mit rein heuristischen Methoden, teilweise mit Unterstützung externer Datenquellen und wirkt ebenso dem Mangel an Trainingsdokumenten entgegen.
Deep Learning
In diesem Schritt durchläuft das Dokument unser entwickeltes Deep Learning Modell für Natural Language Processing. Als Ergebnis liefert es für jedes einzelne Wort des Eingabedokuments und für jede einzelne gesuchte Information eine Wahrscheinlichkeitsangabe: Die Wahrscheinlichkeit, ob es sich hierbei um eine der gesuchten Informationen handeln kann oder nicht.
Post Processing
Die Vielzahl vom Modell ermittelten Wahrscheinlichkeiten werden analysiert und ausgewertet. Zusätzlich helfen heuristische Plausibilitätsprüfungen die Qualität der Ergebnisse noch zu steigern. Unsichere Ergebnisse werden markiert und können in einem weiteren Schritt einer Verarbeitung mit möglicher manueller Nachkontrolle zugeführt werden.
Resultat
Im letzten Schritt werden die extrahierten Informationen zusammengefasst und der Schnittstelle zur Weiterverarbeitung zurückgeliefert.
Die Ergebnisse
Erzielte Genauigkeiten
Die folgende Grafik zeigt die Genauigkeit des Modells ausgewählter Informationen in Abhängigkeit von der Anzahl der Trainingsdokumente. Deutlich zu erkennen ist eine bereits relativ hohe Genauigkeit bei einer geringen Anzahl von Dokumenten. Die Tabelle selbst wurde mittels Cross-Validation Methode erstellt. Dabei wird das Modell vielfach mit einer unterschiedlichen Auswahl von Trainings- und Validierungsdokumenten getestet und die Ergebnisse gemittelt.
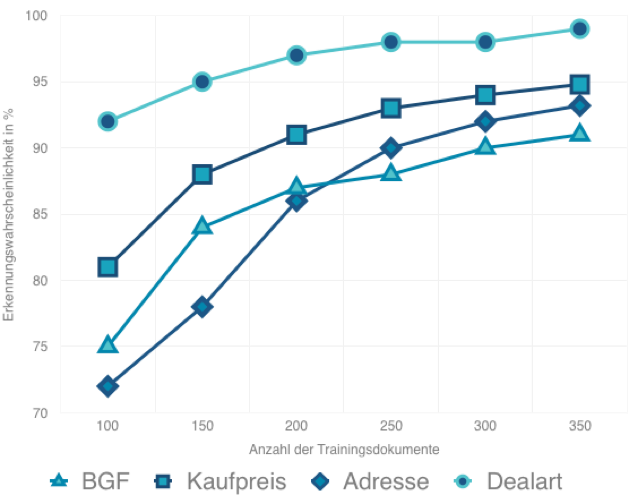 Darstellung 3: Erzielte Genauigkeiten
Darstellung 3: Erzielte Genauigkeiten
Herausforderungen
Bei der Umsetzung dieses Projektes standen uns die unterschiedlichsten Herausforderungen gegenüber.
- Knowhow-Aufbau: Tiefgreifende Kenntnisse über fast.ai sind notwendig, um Anpassungen an ULMFiT im erforderlichen Ausmaß vorzunehmen.?
- Daten: Immobilienexposés enthalten manchmal Angaben zu mehreren Objekten. Zur Unterscheidung welche Information welchem Objekt zuzuordnen sind, würden wesentlich mehr Trainingsdaten notwendig. Die Vorzüge des Transfer Learning greifen hier nicht.?
- Labeln: Fehler beim Labeln werden, wenn überhaupt, erst beim Analysieren der Fehler des Modells erkannt und bedingen zeitaufwendige Korrekturen, wiederholtes Anstoßen von Trainingszyklen und neuerliche Überprüfungen getunter Hyperparameter.?
- OCR: Die Suche nach einem geeigneten OCR Service war unerwartet aufwändig. Um toleranter gegenüber fehlerhaften Textumwandlungen zu sein, haben wir zuletzt zwei OCR Services parallel eingesetzt.?
- Geringe Anzahl von Trainingsdokumenten: Drei Strategien haben letztendlich zu einer erfolgreichen Umsetzung geführt. Die Einbindung eines Sprachmodells (Transfer Learning), das Taggen der Eingabedokumente und nachträgliche heuristische Plausibilitätsprüfungen.?
Angekommen? Noch lange nicht, aber eine kurze Zwischenrast sei erlaubt.
Das ist erst der Anfang. Wir wissen wie die Reise aussehen kann um mit gerade noch ausreichendem Grundmaterial AI Lösungen umzusetzen.
Das haben wir erreicht:
- Label-Oberfläche: Flexible und erweiterbare Label-Plattform für individuelles Labeln.
- Tagging-Prozess: Automatisiertes Kennzeichnen der grundlegenden Informationen (Adresse, Name, Zahl, Wort) ist vorhanden und beliebig erweiterbar.
- Hyperparameter Optimierung: Pragmatischer Optimierungsprozess für das Ausschöpfen der Potentiale der Trainingsdaten bei geringer Anzahl.
- Ergebnisbewertung: Interface für Trainings- und Optimierungsvorgänge.
Dranbleiben und wissen wie es weitergeht! Damit wird Ihre Lernkurve auch in unbekannten Bereichen steiler! NLP wird das neue Wunderkind der Branchen zur KI-basierten individuellen Verarbeitung von riesigen Dokumentenbergen.
Unser Lösungspartner AI Consulting - goodguys.cc
Diese Artificial Intelligence und Machine Learning Ansätze sind schnell, flexibel und verständlich. Es muss Spaß machen mit Wissen, Technik und Verve das Thema nutzbar zu gestalten. Genau so haben wir auch hier mit Hr. Dr. Füricht von den Goodguys erfolgreich zusammen gearbeitet! Das AI Netzwerk: https://goodguys.cc
Über Calista
Wir widmen uns seit über vier Jahren dem Aufbau von AI-Knowhow. Dabei setzen wir sowohl auf klassisches maschinelles Lernen als auch auf Deep Learning Methoden. Neben dem Schwerpunkt NLP beschäftigen wir uns auch mit den DL Themenbereichen Visual Imaging und Structured Data. We Go The AI Way: https://calista.at